|
|
 |
|
|
What is it?The Cambridge Learner Corpus (CLC) is a large collection of examples of English writing from learners of English all over the world. It contains over 30 million words and it is expanding all the time. It forms part of the Cambridge International Corpus (CIC). It has been built by Cambridge University Press and Cambridge ESOL (part of UCLES, the University of Cambridge Local Examination Syndicate). The English in the CLC comes from anonymised exam scripts written by students taking Cambridge ESOL English exams around the world. Exams currently represented in the CLC are:
The CLC currently contains scripts from over
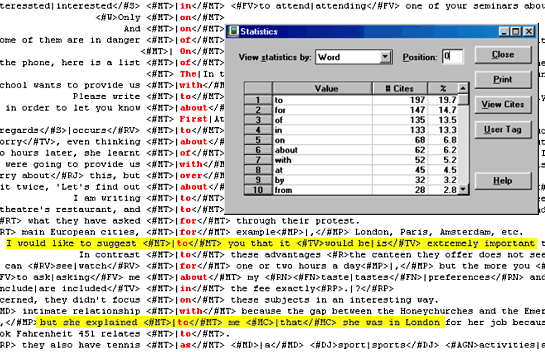
For instance we have over half a million words of text from Japanese speakers, and over 4 million words from Spanish speakers, split between Spain and South America. Each script is coded with information about the student's first language, nationality, level of English, age, etc. This means we can focus in on particular types of learner and see what they get right and what they get wrong. This helps us to produce more specifically targeted materials for these learners with more help just where they need it! Who can use the CLC?Currently, it can only be used by authors and writers working for Cambridge University Press and by members of staff at Cambridge ESOL. How is the CLC used?Authors, editors and lexicographers use the CLC when they are working on books for Cambridge University Press. They can search the CLC to find examples of how learners use English. They can find out which words, patterns and grammatical structures are used successfully. Even more usefully than this, they can find out which areas of English cause the biggest problems for learners. This information helps us to present the right information in the dictionaries and ELT course books that use the CLC. Cambridge ESOL use the data from the CLC to answer questions about the way that students learn at different levels. They also use it to check that the assessment of students' exams is done consistently from country to country and from year to year. Cambridge Learner Error Coding SystemA unique feature of the CLC is that over 30 million words or about 95,000 scripts, have been coded with a Learner Error Coding system devised by Cambridge University Press. This means that we can see which words or structures produce the most errors in Learner English. It also means that we can search for particular errors and always find plenty of examples. Here's what a Cambridge University Press author would see if they wanted to find out where learners make the mistake of missing out a preposition. The words in red are the prepositions that the learners should have used but didn't and <#MT> is the code for a missing preposition. Look at the lines of learner text around the statistics window to see some common mistakes like these: " …I would like to suggest you that it is extremely important…" " …but she explained me that she was in London…"
Now look at the grey statistics window which is on top of the lines of text. It shows which preposition is missed out most frequently. You can see 'to' at the top of the list — it was omitted 197 times in a sample of 1000 cites. The program could equally show which words most frequently have a preposition omitted after them. In this sample 'explain' was the word where students had most frequently omitted the preposition. Again, we could also use the program to find out which level of students make this mistake most — or which nationality — and lots more besides. We can see which errors are typical of different learner levels or of particular language groups because all the scripts have information about the first language and English level of the writer. This means that when we produce a book designed for a particular level, eg Upper Intermediate, we can look at all the scripts written by Upper Intermediate learners and very easily see exactly what mistakes they make. In this way we can make sure the book contains appropriate help for an Upper Intermediate student. In the same way, when we write a book to support a particular exam, (eg PET, Preliminary English Test or CPE, Certificate of Proficiency in English) we can look at scripts from that exam and see exactly what are the areas that cause students problems and be sure to cover those areas in Cambridge books. And again, when we produce a book designed for a particular country, we can look at all the mistakes commonly made by speakers in that language area and ensure that we give them the help they need. This means that students can be sure that Cambridge University Press materials will cover exactly the areas of language that they find difficult and teachers can be confident that books will cover the specific areas that cause problems for their students. |
|
||||||||||||||||||